前言
当初拿到这份讲义,翻到最后看到这题两眼一黑,如今终于可以面对,说实话这道大题超级综合,各种知识点的设计,包括计组的题目说实话每一句话都是知识点,给我们上课的M佬说实话真的不错,每听一遍课都有新的感悟
还以为考研期间没机会写文章了,然而这道大题完全值得一篇文章来精析
存储器大Boss
1. 主考点:刷新周期与存储周期 & 刷新计数器位数

由于 8 块 DRAM 组成 2GB 内存条,可得每个 DRAM 容量为 256 MB(2^28)
=> DRAM 芯片每个 2^14 行 2^14 列,即 16384 行 16384 列
再有异步刷新,且题目给出刷新周期为 10.485760ms,由王道P68页可知 两行之间刷新间隔为刷新周期除行数
=> 10.485760 / 16384 = 640ns
- 题目第一问是时间间隔多少个存储周期?那么我们再除存储周期40ns就可得间隔多少个存储周期
=> 640 / 40 = 16个存储周期
求间隔存储周期总结
- 求DRAM行数
- 算出两行间隔时间
- 题目要求有多少个存储周期,那么再除题目给出的存储周期即可
- 题目第二问 DRAM 中刷新计数器多少位?刷新计数器是为了记录cache行刷新
=> 刷新计数器即为行的位数也就是 14 位
2. 主考点:行缓冲容量计算 & 地址引脚复用

- 如第一解可知 DRAM 中每行有 16384 个存储单元,每个存储单元 1 字节
=> 行缓存寄存器大小为 16384 字节
- 再由第一解可知每个DRAM芯片256MB,也就是 2^28,而地址引脚复用技术,行地址和列地址通过相通引脚分先后两次输入(王道书P89)
=> DRAM芯片的地址引脚个数为14个
3. 主考点:主存与Cache的地址结构
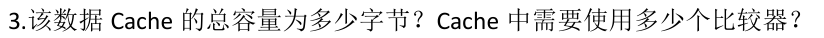
算Cache前我觉得都理清一下基础信息:Cache行大小、Cache行数、Cache组号、主存地址结构
- Cache行的大小题干给出是64bit,那么就是8byte
- 由Cache数据区有512B且一行8byte,可知 512 / 8 = 64 行
- 由于4路组相连,可知 64 / 4 = 16 组
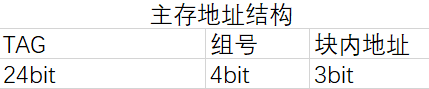
- 由于题目是组相连映射,且知组相连映射的地址结构为 TAG + 组号(4bit) + 块内映射(3bit)
16组 => 4bit组号,8byte大小 => 3bit块内映射,由于内存条为2GB,所以主存位数31位(自己做错的地方)
TAG = 31 - 4 - 3 = 24bit
- 第二问求多少个比较器,因为是四路组相连
所以可以直接得知4个比较器
- 第一问求数据Cache总容量,数据Cache总容量 = 标记阵列 + 数据阵列(题干已给出为512B)
主要就是在标记阵列的求法了,标记阵列 = 有效位 + 脏位 + 算法替换位 + TAG
- 有效位
所有Cache行都会有一个有效位,所以这里 1bit
- 脏位
由题干可知采用了回写策略,所以脏位 1bit
- 算法替换位
由于是4路组相连,该计数器的位数与Cache组大小有关,所以为 2bit
- TAG
Cache的TAG,由主存地址结构的TAG推出,24bit
综上,数据 Cache 的标记矩阵为 (24 + 2 + 1 + 1) * 64 = 1792bit,也就是64行Cache行的总标记阵列,而数据阵列为512byte也就是4096bit,于是数据Cache总容量大小为 4096 + 1792 = 5888bit
4. 主考点:CPU访问Cache & 突发传送 & 轮流启动
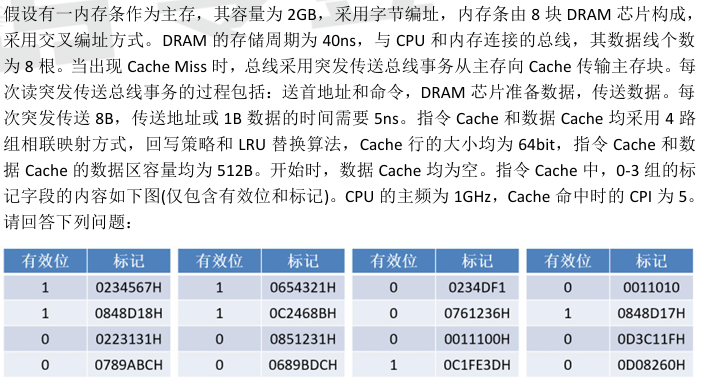
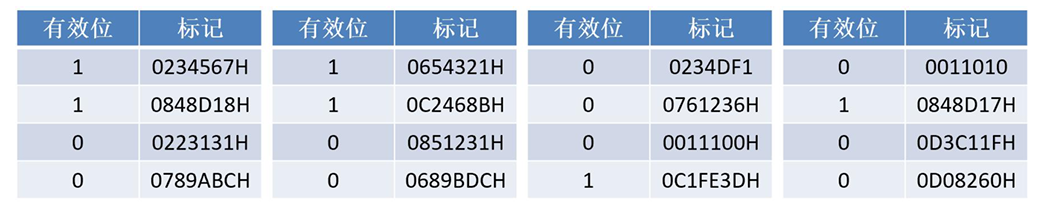
请问CPU读取指令A和指令B所需要的时间为多少?(指令Cache中,0-3组的标 记字段的内容如下图(仅包含有效位和标记))
- 第一问:CPU读取指令A(地址:6123458DH)所需时间
这里是卡我的第一个点,首先看这个地址要以更高的一个维度,整理一下知识点,当我们有了主存地址,对应不同的情况有不同的理解角度,考研计组中有三种方式
注意主存地址要根据不同映射方式解析为不同的地址结构,而该题组相连映射都是如此,也不要和Cache内的标记阵列弄混
- 考察地址到Cache映射的时候,解析方式为 TAG + 组号 + 块内偏移
- 通过组号找到对应组,再通过TAG进行标记找到目标Cache行,而块内偏移就是为了找到Cache行的某个字节
- 考察DRAM芯片交叉编址,解析方式是 芯片地址 + 组号
- 考虚拟存储系统,解析方式为 页号 + 页内地址
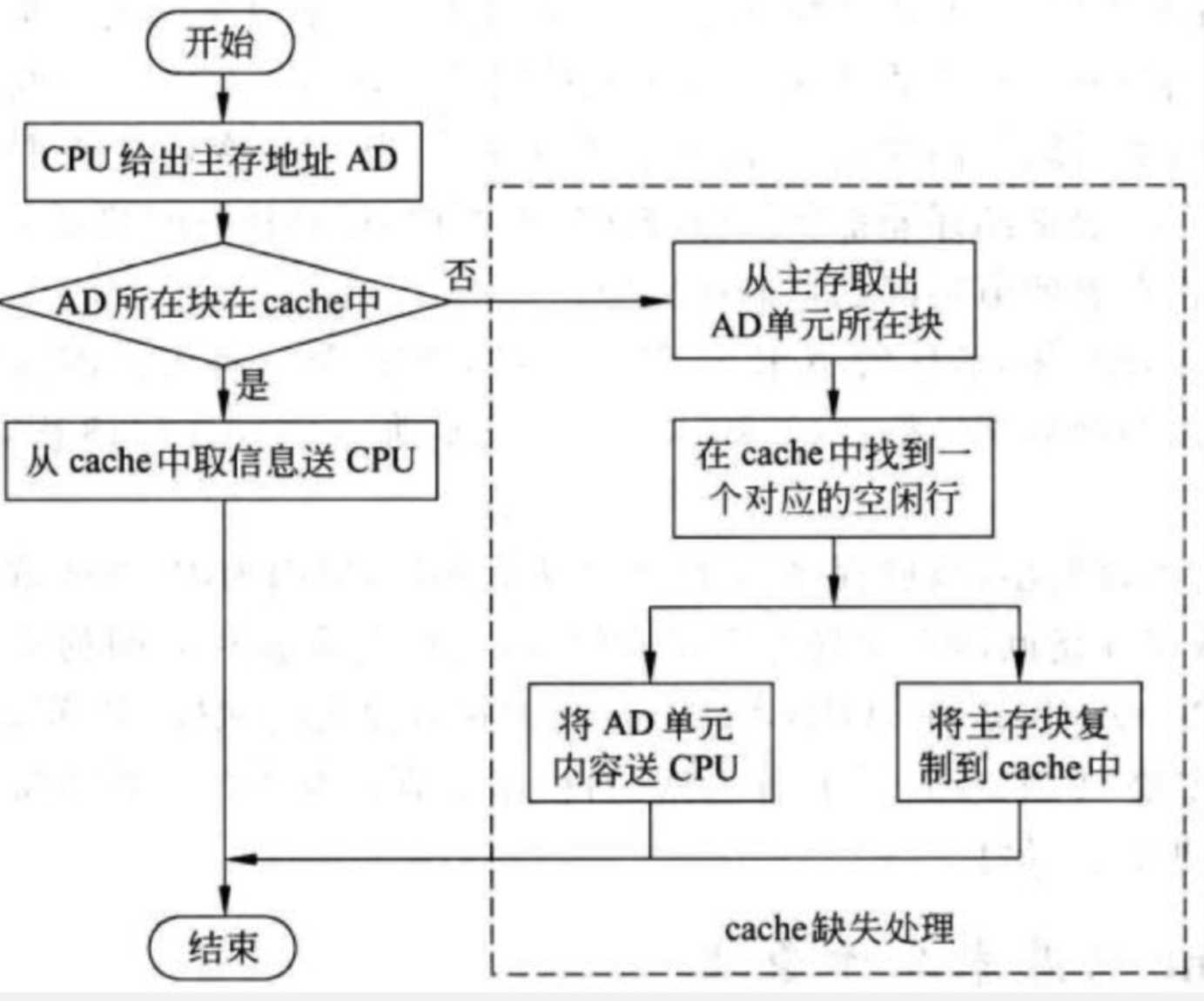
该问CPU读取时间显然是让我们模拟读取过程并计算,如图
先访问Cache,也就是我刚刚总结的第一种情况,6123458DH先全部转为二进制,高24位为0C2468B,低7位(前四位是0001)
- 于是在0001组也就是题目给出的前四个Cache组的第二列
- 再通过TAG比对,发现有效位为1,Cache命中
题干给出CPU主频为1GHz => 主频的倒数即为时钟周期,那么1GHz倒数即为 1ns
题干给出Cache命中的CPI(一条指令所要的时钟周期)为5
=> CPU读取指令A所要的时钟周期为 5 x 1 = 5ns
- 第二问:CPU读取指令B(地址:6841301BH)所需时间
同样先访问Cache,6123458DH先全部转为二进制,高24位为0D08260H,低7位(前四位是0011),于是在0011组有对应TAG,但有效位为0,未命中
由题干可知
当出现CacheMiss时,总线采用突发传送总线事务从主存向Cache传输主存块。每次读突发传送总线事务的过程包括:送首地址和命令,DRAM芯片准备数据,传送数据。每次突发传送8B,传送地址或1B数据的时间需要5ns
总结一下突发传送总线数据
- CPU给主存传地址
- 连续传送主存块的存储单元
(PPT上讲的突发传送是送地址和存储点单元,这只是一般情况,具体题目具体情况分析)
这里也有一个需要注意的地方,题干中也给出数据线个数为8根,也就是8bit,而主存块个数为64bit(8byte),而同时启动要求是数据根数必须和主存块位数一样,所以不考虑同时启动,该题就是轮流启动
那么如图,由于未命中,所以从CPU传地址到主存,读取DRAM芯片,再到主存存入Cache的轮流启动过程

最后CPU读取指令B,也就是当前已经从主存取来的数据由题干可知只要5ns
=> 5 + 85 = 90ns(用5ns访问Cache,85ns完成突发传送)
5. 主考点:Cache存入机制

主存块大小为8B,一个int类型数据为4B,一个主存块可以包含2个int类型数据
=> 数组A存放在 128 / 2 = 64 个主存块中
题干中可知
开始时,数据Cache均为空。
所以当读取A[0]时候,Cache miss,用时90ns才能读到,而读A[1]时,这个时候该数据已经在Cache中,所以只要5ns读入
=> 也就说一个主存块中的两个int类型数据需要的总时间就是 90ns + 5ns = 95ns
于是可知,访问64个主存块中存储的 128 个int类型数据总时间为 95 * 64 = 6080ns
后记
终于写完了…差不多写了三个多小时??昨天下午光理解就花了好久,但感觉也非常值得,这次复盘把很多知识点都理了一遍,可以说是基础轮存储器大复盘的一个收尾,之后再遇到类似的题目就不怕了,这么huge的一个题目解决了,其他题目再多也不会多于此了。 – 2024.5.8 12:11

About this Post
This post is written by P.Z, licensed under CC BY-NC 4.0.