这题拖了好久,原因未知,总感觉充满了不想复现的恐惧,昨天硬着头皮复现几乎半天,终于搞懂了,这题简直是我思维的bug,答案就在眼前,可无法去思考理解,但总之只要愿意花时间,没什么是完不成的。
还有个好用的恢复符号工具, https://github.com/aliyunav/Finger ,记得关梯子
0x00 日常查壳 无壳64位
0x01 setjmp/longjmp 推荐这篇文章 可以去了解一下这个技术的实现,总之是setjmp设置一个记录点,再longjmp跳回去
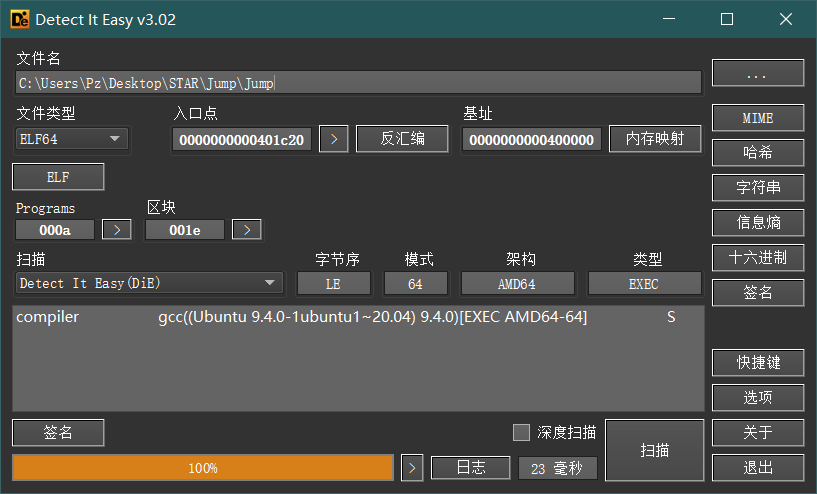
随便跟入一个setjmp可以发现,这里保存了setjmp后的eip,也就是setjmp后的地址,不过做了点混淆?(在longjmp的时候就比较清楚了
这里是rdi + 38h的位置,这里所有的操作是在保存线程上下文,这里我们暂且称为env ,到时候通过这个env 来恢复到这里(也就是longjmp跳回来
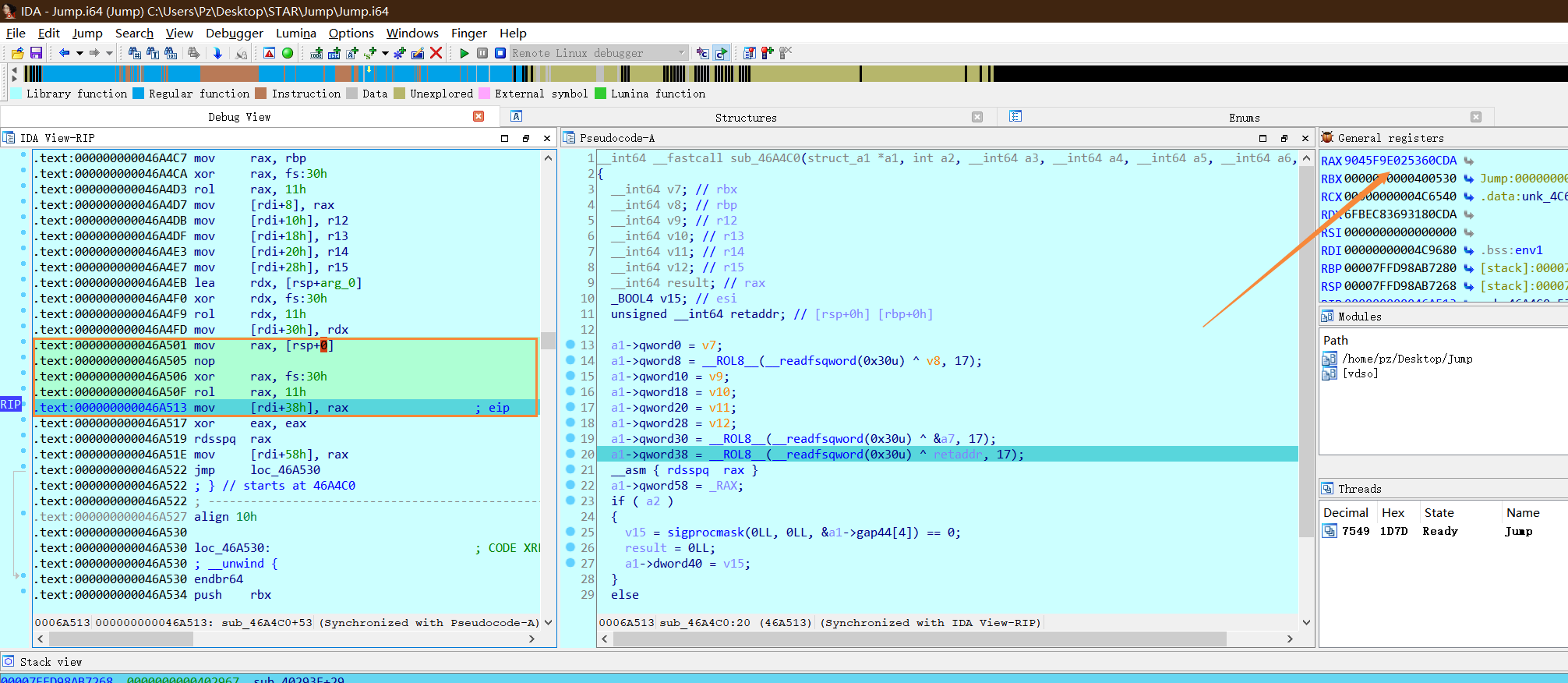
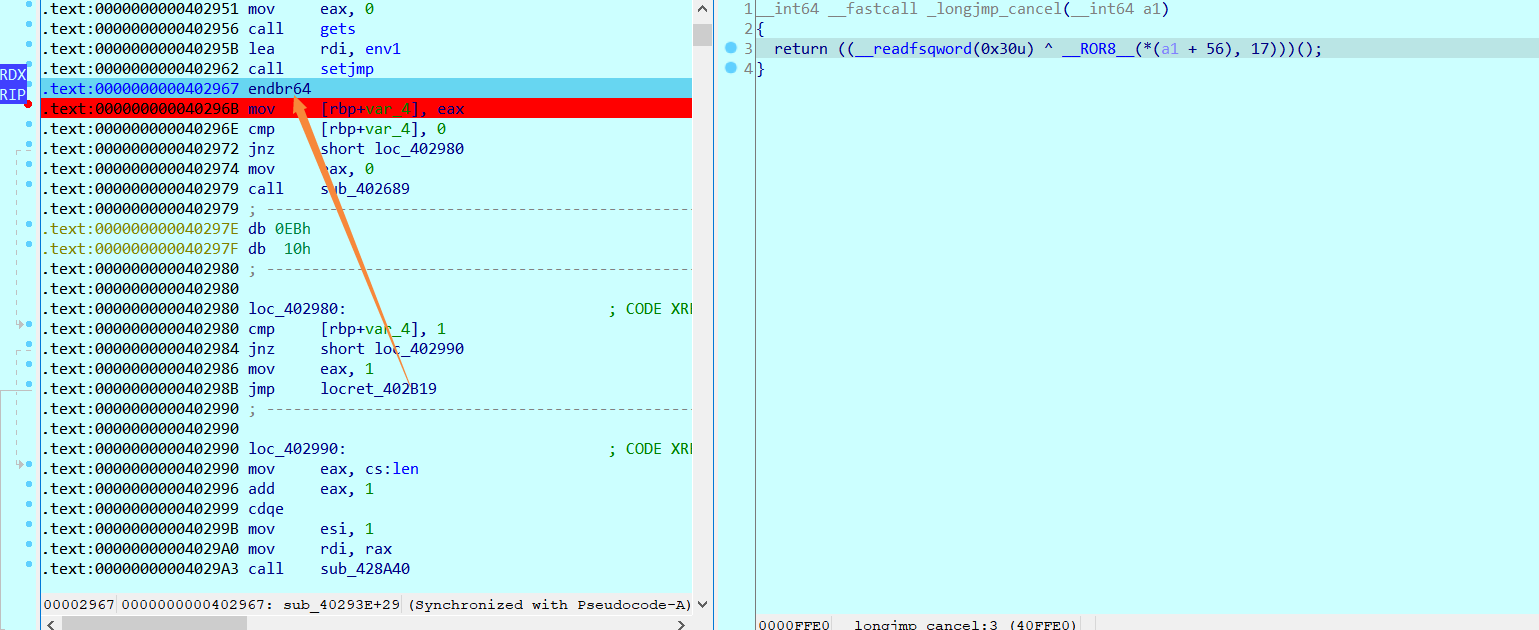
随后跟随到longjmp的这里
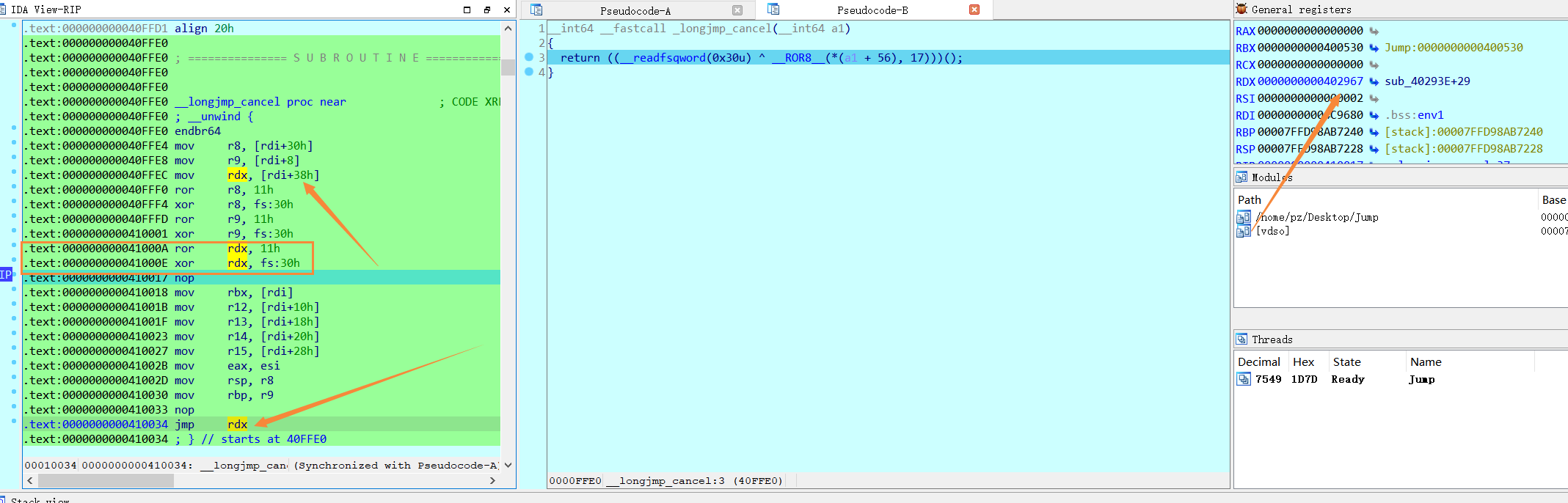
注意我们也同样是rdi + 38h的地方取出,再经过如上的操作,跳到这个rdx地址,即是call setjmp之后的地址
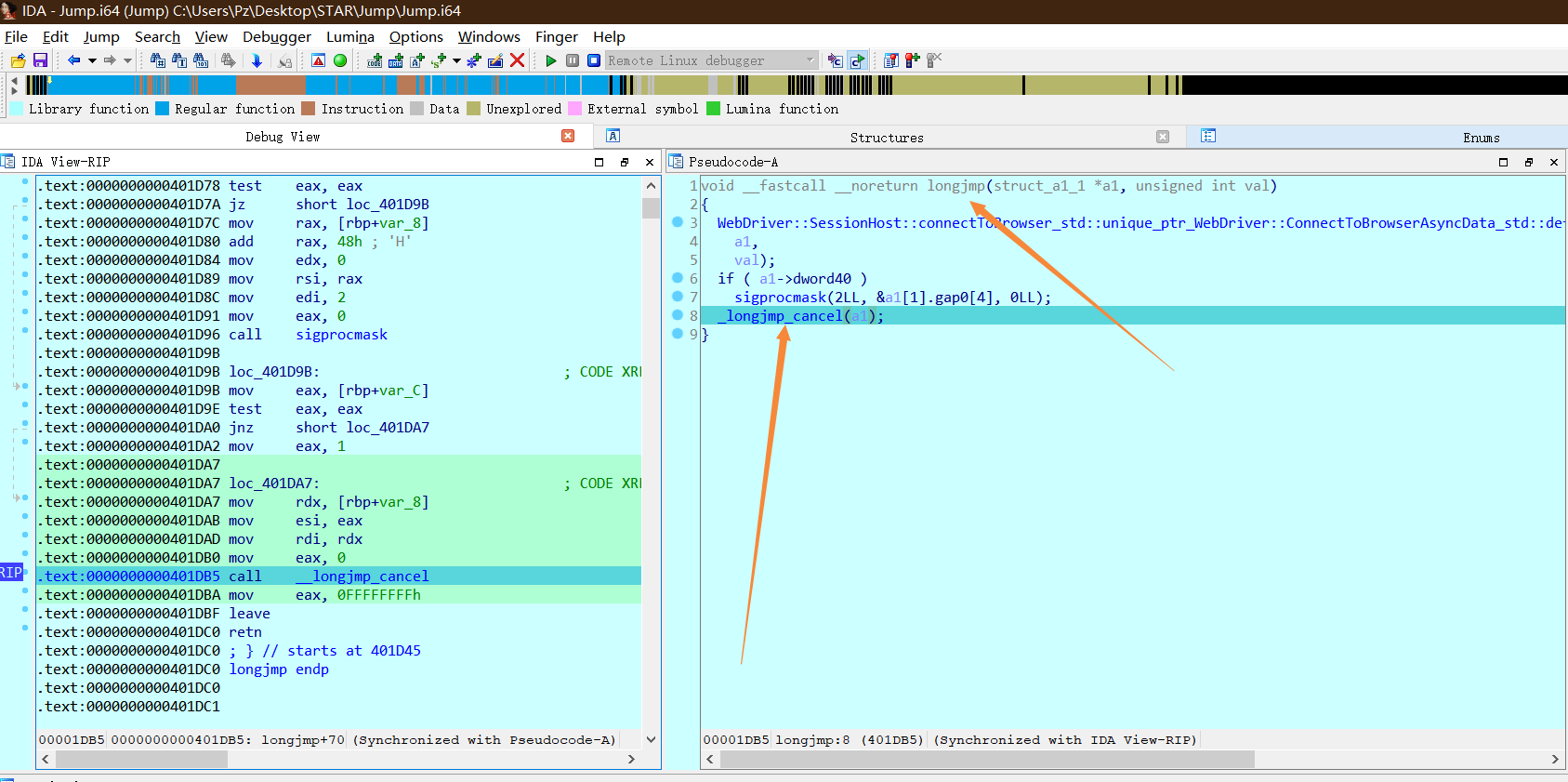
继续跟随可以发现成功跳到了call setjmp之后的地址,这边有个有趣的指令就是endbr64
查询指令可知,经过间接跳转(setjmp/longjmp)需要有一条指令对应endbr64指令来回应间接跳转,如果不是endbr64那么说明程序控制流被劫持了
参考文章
于是只要经过几遍调试,即可熟悉setjmp/longjmp的跳转,通过setjmp和longjmp后的第一个参数都是所对应的上下文,对应的env对应设置哪跳到哪
注意longjmp的第二个参数是给setjmp的返回值
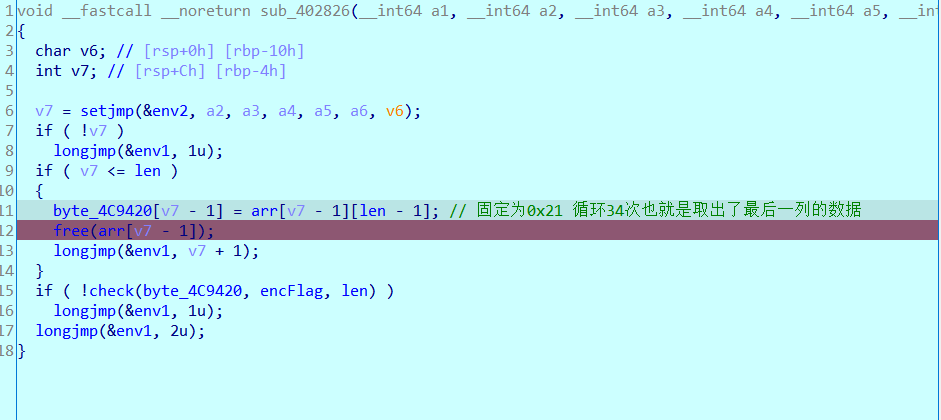
0x02 分析流程 我们的输入长度为34,setjmp与longjmp的配合跳转通过在402689函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void __fastcall __noreturn sub_402689 (__m128 a1) { __int64 v1; __int64 v2; __int64 v3; __int64 v4; int v5; __int64 v6; __int64 v7; __int64 v8; __int64 v9; char v10; char v11; signed int v12; if ( strchr (&input, 2LL ) || strchr (&input, 3LL ) ) longjmp(&env1, 1u ); if ( !setjmp(&env3, 3LL , v1, v2, v3, v4, v10) ) longjmp(&env1, 2u ); sprintf (off_4C9400, "%c%s%c" , 2 , &input, 3 , v5); v12 = setjmp(&env3, "%c%s%c" , v6, v7, v8, v9, v11); if ( !v12 ) longjmp(&env1, 1u ); if ( v12 > 0 ) { input_arr = sub_428A40(len + 1 , 1uLL ); j_strcat_ifunc_0(input_arr, off_4C9400 + v12 - 1 , off_4C9400 + v12 - 1 , a1); if ( v12 > 1 ) strncat (input_arr, off_4C9400, v12 - 1 ); arr[v12 - 1 ] = input_arr; } longjmp(&env1, v12); }
找到拼接的input_arr可以查看一下地址表,然后提取出来
1 2 3 4 5 6 7 8 9 10 11 12 #include <idc.idc> static main () { auto addr = 0xB12100 ; auto i; for ( i = addr ; i < 0xB1221F ; i = i + 0x8 ) { Message("0x%X, " , get_wide_dword(i)); } }
然后提取字符串(接下来的数据借用了zsky师傅的数据,文末有链接)
1 2 3 4 5 6 addr =[0xB12220 , 0xB12850 , 0xB12610 , 0xB12310 , 0xB124C0 , 0xB12670 , 0xB12430 , 0xB12400 , 0xB123A0 , 0xB12580 , 0xB127F0 , 0xB126D0 , 0xB12760 , 0xB122E0 , 0xB126A0 , 0xB122B0 , 0xB12790 , 0xB12550 , 0xB12700 , 0xB12460 , 0xB127C0 , 0xB12640 , 0xB12370 , 0xB12250 , 0xB12820 , 0xB124F0 , 0xB125E0 , 0xB12490 , 0xB12340 , 0xB125B0 , 0xB123D0 , 0xB12730 , 0xB12280 , 0xB12520 , 0xB12880 ] for i in range (34 ): tmp = b"" for j in range (34 ): tmp += get_bytes(addr[i] + j, 1 ) print (tmp)
就可以形成这样的数据,就如那个函数一样把字符左移放后左移放后,这样进行了34次
本身保证每一行每一位不数据不同,又经过34次移位保证了每一列数据也不同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 b'\x02985236147adgjlqwesxzcvbnmfuiopvx\x03' b'985236147adgjlqwesxzcvbnmfuiopvx\x03\x02' b'85236147adgjlqwesxzcvbnmfuiopvx\x03\x029' b'5236147adgjlqwesxzcvbnmfuiopvx\x03\x0298' b'236147adgjlqwesxzcvbnmfuiopvx\x03\x02985' b'36147adgjlqwesxzcvbnmfuiopvx\x03\x029852' b'6147adgjlqwesxzcvbnmfuiopvx\x03\x0298523' b'147adgjlqwesxzcvbnmfuiopvx\x03\x02985236' b'47adgjlqwesxzcvbnmfuiopvx\x03\x029852361' b'7adgjlqwesxzcvbnmfuiopvx\x03\x0298523614' b'adgjlqwesxzcvbnmfuiopvx\x03\x02985236147' b'dgjlqwesxzcvbnmfuiopvx\x03\x02985236147a' b'gjlqwesxzcvbnmfuiopvx\x03\x02985236147ad' b'jlqwesxzcvbnmfuiopvx\x03\x02985236147adg' b'lqwesxzcvbnmfuiopvx\x03\x02985236147adgj' b'qwesxzcvbnmfuiopvx\x03\x02985236147adgjl' b'wesxzcvbnmfuiopvx\x03\x02985236147adgjlq' b'esxzcvbnmfuiopvx\x03\x02985236147adgjlqw' b'sxzcvbnmfuiopvx\x03\x02985236147adgjlqwe' b'xzcvbnmfuiopvx\x03\x02985236147adgjlqwes' b'zcvbnmfuiopvx\x03\x02985236147adgjlqwesx' b'cvbnmfuiopvx\x03\x02985236147adgjlqwesxz' b'vbnmfuiopvx\x03\x02985236147adgjlqwesxzc' b'bnmfuiopvx\x03\x02985236147adgjlqwesxzcv' b'nmfuiopvx\x03\x02985236147adgjlqwesxzcvb' b'mfuiopvx\x03\x02985236147adgjlqwesxzcvbn' b'fuiopvx\x03\x02985236147adgjlqwesxzcvbnm' b'uiopvx\x03\x02985236147adgjlqwesxzcvbnmf' b'iopvx\x03\x02985236147adgjlqwesxzcvbnmfu' b'opvx\x03\x02985236147adgjlqwesxzcvbnmfui' b'pvx\x03\x02985236147adgjlqwesxzcvbnmfuio' b'vx\x03\x02985236147adgjlqwesxzcvbnmfuiop' b'x\x03\x02985236147adgjlqwesxzcvbnmfuiopv' b'\x03\x02985236147adgjlqwesxzcvbnmfuiopvx'
再接着跟有个401F62函数,经过了快速排序处理,数据如下(这是通过字典序 排序后的,注意是行排序)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 b'\x02985236147adgjlqwesxzcvbnmfuiopvx\x03' b'985236147adgjlqwesxzcvbnmfuiopvx\x03\x02' b'85236147adgjlqwesxzcvbnmfuiopvx\x03\x029' b'5236147adgjlqwesxzcvbnmfuiopvx\x03\x0298' b'236147adgjlqwesxzcvbnmfuiopvx\x03\x02985' b'36147adgjlqwesxzcvbnmfuiopvx\x03\x029852' b'6147adgjlqwesxzcvbnmfuiopvx\x03\x0298523' b'147adgjlqwesxzcvbnmfuiopvx\x03\x02985236' b'47adgjlqwesxzcvbnmfuiopvx\x03\x029852361' b'7adgjlqwesxzcvbnmfuiopvx\x03\x0298523614' b'adgjlqwesxzcvbnmfuiopvx\x03\x02985236147' b'dgjlqwesxzcvbnmfuiopvx\x03\x02985236147a' b'gjlqwesxzcvbnmfuiopvx\x03\x02985236147ad' b'jlqwesxzcvbnmfuiopvx\x03\x02985236147adg' b'lqwesxzcvbnmfuiopvx\x03\x02985236147adgj' b'qwesxzcvbnmfuiopvx\x03\x02985236147adgjl' b'wesxzcvbnmfuiopvx\x03\x02985236147adgjlq' b'esxzcvbnmfuiopvx\x03\x02985236147adgjlqw' b'sxzcvbnmfuiopvx\x03\x02985236147adgjlqwe' b'xzcvbnmfuiopvx\x03\x02985236147adgjlqwes' b'zcvbnmfuiopvx\x03\x02985236147adgjlqwesx' b'cvbnmfuiopvx\x03\x02985236147adgjlqwesxz' b'vbnmfuiopvx\x03\x02985236147adgjlqwesxzc' b'bnmfuiopvx\x03\x02985236147adgjlqwesxzcv' b'nmfuiopvx\x03\x02985236147adgjlqwesxzcvb' b'mfuiopvx\x03\x02985236147adgjlqwesxzcvbn' b'fuiopvx\x03\x02985236147adgjlqwesxzcvbnm' b'uiopvx\x03\x02985236147adgjlqwesxzcvbnmf' b'iopvx\x03\x02985236147adgjlqwesxzcvbnmfu' b'opvx\x03\x02985236147adgjlqwesxzcvbnmfui' b'pvx\x03\x02985236147adgjlqwesxzcvbnmfuio' b'vx\x03\x02985236147adgjlqwesxzcvbnmfuiop' b'x\x03\x02985236147adgjlqwesxzcvbnmfuiopv' b'\x03\x02985236147adgjlqwesxzcvbnmfuiopvx'
于是继续跟随我们进入了402826函数,获得了最后一列数据
0x03 GetFlag 由此我们来获取flag,那么其实也就是恢复flag的顺序,这里看了各路师傅的wp,学习到两种解法
首先希望在看我WP的师傅把这个想象成一个字符矩阵 ,我们现在所拥有的是最后一列(可见qsort后的数据)
我们的目标是恢复第一行
Burrows-Wheeler变换 第一种比较直观,看完这篇文章 就秒懂了
当我们通过排序恢复了第一列,再与最后一列拼接(此时最后一列在第一列前面),再进行排序,恢复了第二列(因为是字典排序)
那么现在有第一列和第二列再在第一列前拼接上最后一列,再继续排序,又可以恢复第三列
EXP
1 2 3 4 5 6 7 8 9 10 11 12 s = '\03jmGn_=uaSZLvN4wFxE6R+p\02D2qV1CBTck' lst = [[0 ]] * 34 for i in range (len (lst)): lst[i] = s[i] tmp = [[0 ]] * 34 for i in range (len (tmp)): tmp[i] = s[i] for k in range (34 ): lst.sort() for i in range (len (lst)): lst[i] = tmp[i] + lst[i] print (lst)
未命名解法 首先得心中有张图也就是qsort之后的数据,排序完之后,不管行的顺序怎么变,每一行的数据都是一样的,只是顺序不同
每个字符与他的前一位一直都是紧挨着的
由此我们已知最后一位的0x3,通过此我们从第一列找到0x3
那么与0x3相同的行的最后一位就是0x3的前一位
拿到此数据我们放到flag的最后一位
再拿刚刚获取的flag最后一位再去第一列找,找到数据又是相同行的最后一位是他的前一位(重复以此)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 b'\x02985236147adgjlqwesxzcvbnmfuiopvx\x03' b'985236147adgjlqwesxzcvbnmfuiopvx\x03\x02' b'85236147adgjlqwesxzcvbnmfuiopvx\x03\x029' b'5236147adgjlqwesxzcvbnmfuiopvx\x03\x0298' b'236147adgjlqwesxzcvbnmfuiopvx\x03\x02985' b'36147adgjlqwesxzcvbnmfuiopvx\x03\x029852' b'6147adgjlqwesxzcvbnmfuiopvx\x03\x0298523' b'147adgjlqwesxzcvbnmfuiopvx\x03\x02985236' b'47adgjlqwesxzcvbnmfuiopvx\x03\x029852361' b'7adgjlqwesxzcvbnmfuiopvx\x03\x0298523614' b'adgjlqwesxzcvbnmfuiopvx\x03\x02985236147' b'dgjlqwesxzcvbnmfuiopvx\x03\x02985236147a' b'gjlqwesxzcvbnmfuiopvx\x03\x02985236147ad' b'jlqwesxzcvbnmfuiopvx\x03\x02985236147adg' b'lqwesxzcvbnmfuiopvx\x03\x02985236147adgj' b'qwesxzcvbnmfuiopvx\x03\x02985236147adgjl' b'wesxzcvbnmfuiopvx\x03\x02985236147adgjlq' b'esxzcvbnmfuiopvx\x03\x02985236147adgjlqw' b'sxzcvbnmfuiopvx\x03\x02985236147adgjlqwe' b'xzcvbnmfuiopvx\x03\x02985236147adgjlqwes' b'zcvbnmfuiopvx\x03\x02985236147adgjlqwesx' b'cvbnmfuiopvx\x03\x02985236147adgjlqwesxz' b'vbnmfuiopvx\x03\x02985236147adgjlqwesxzc' b'bnmfuiopvx\x03\x02985236147adgjlqwesxzcv' b'nmfuiopvx\x03\x02985236147adgjlqwesxzcvb' b'mfuiopvx\x03\x02985236147adgjlqwesxzcvbn' b'fuiopvx\x03\x02985236147adgjlqwesxzcvbnm' b'uiopvx\x03\x02985236147adgjlqwesxzcvbnmf' b'iopvx\x03\x02985236147adgjlqwesxzcvbnmfu' b'opvx\x03\x02985236147adgjlqwesxzcvbnmfui' b'pvx\x03\x02985236147adgjlqwesxzcvbnmfuio' b'vx\x03\x02985236147adgjlqwesxzcvbnmfuiop' b'x\x03\x02985236147adgjlqwesxzcvbnmfuiopv' b'\x03\x02985236147adgjlqwesxzcvbnmfuiopvx'
1 2 3 4 5 6 7 8 9 10 11 12 13 import copyenc=[0x03 , 0x6A , 0x6D , 0x47 , 0x6E , 0x5F , 0x3D , 0x75 , 0x61 , 0x53 , 0x5A , 0x4C , 0x76 , 0x4E , 0x34 , 0x77 , 0x46 , 0x78 , 0x45 , 0x36 , 0x52 , 0x2B , 0x70 , 0x02 , 0x44 , 0x32 , 0x71 , 0x56 , 0x31 , 0x43 , 0x42 , 0x54 , 0x63 , 0x6B ] c=copy.deepcopy(enc) c.sort() m=[0 ]*34 m[0 ]=2 m[-1 ]=3 for i in range (0x20 ,-1 ,-1 ): p=c.index(m[i+1 ]) m[i]=enc[p] print (bytes (m))
或者正着往后推!道理相同
1 2 3 4 5 6 7 8 9 10 sort_enc = list (b'\x02\x03+1246=BCDEFGLNRSTVZ_acjkmnpquvwx' ) enc = list (b'\x03jmGn_=uaSZLvN4wFxE6R+p\x02D2qV1CBTck' ) input = [0 ] * 34 input [0 ] = 2 for i in range (33 ): t = enc.index(input [i]) input [i + 1 ] = sort_enc[t] print (bytes (input ))
参考文章 https://www.52pojie.cn/thread-1623713-1-1.html#42357189_jump
https://lu1u.xyz/2022/04/19/StarCTF-2022/
https://moodyblue.cn/category/%E6%98%9FCTF-Rever/#toc-heading-3
http://sma11cc.cc/2022/04/19/CTF%202022%2094d97/