今天把基本的流程过了一遍,先贴所学习到的源码(开始在我的Ubuntu21旅程!)
Server
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| #include <stdio.h>
#include <iostream>
#include <stdlib.h>
#include <netinet/in.h>
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <string.h>
using namespace std;
#define PORT 1234
int main()
{
struct sockaddr_in s_in;
struct sockaddr_in c_in;
int l_fd, c_fd;
socklen_t len;
char buf[100];
memset((void *)&s_in, 0, sizeof(s_in));
s_in.sin_family = AF_INET;
s_in.sin_addr.s_addr = INADDR_ANY;
s_in.sin_port = htons(PORT);
l_fd = socket(AF_INET, SOCK_STREAM, 0);
bind(l_fd, (struct sockaddr *)&s_in, sizeof(s_in));
listen(l_fd, 1);
cout << "Wait for you in the galxry." << endl;
while ( 1 )
{
c_fd = accept(l_fd, (struct sockaddr *)&c_in, &len);
while ( 1 )
{
for ( int j = 0; j < 100; j++ )
{
buf[j] = 0;
}
int n = read(c_fd, buf, 100);
if ( !strcmp(buf, "q\n") || !strcmp(buf, "Q\n") )
{
cout << "q pressed\n";
close(c_fd);
break;
}
cout << "P.Z say! " << buf << endl;
write(c_fd, buf, n);
}
}
return 0;
}
|
Client
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| #include <stdio.h>
#include <string.h>
#include <iostream>
#include <stdlib.h>
#include <string>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define BUF_SIZE 100
#define ADDR "127.0.0.1"
#define SERVERPORT 1234
using namespace std;
int main(int argc, char *argv[])
{
int sock;
char opmsg[BUF_SIZE];
char get_msg[BUF_SIZE] = {0};
int write_len;
struct sockaddr_in serv_addr;
sock = socket(PF_INET, SOCK_STREAM, 0);
if (sock == -1)
{
return -1;
}
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr(ADDR);
serv_addr.sin_port = htons(SERVERPORT);
if ( connect(sock, (struct sockaddr*) &serv_addr, sizeof(serv_addr)) == -1 )
{
cout << "connect error\n";
return -1;
}
else
{
cout << "LINKSTART!\n" << endl;
}
while ( 1 )
{
fgets(opmsg, BUF_SIZE, stdin);
write_len = write(sock, opmsg, strlen(opmsg));
if ( !strcmp(opmsg, "q\n") || !strcmp(opmsg, "Q\n") )
{
puts("q pressed\n");
break;
}
else
{
int read_msg_len = read(sock, get_msg, write_len);
cout << "send length: " << write_len << "\nget P.Z say! " << get_msg << endl;
}
}
close(sock);
return 0;
}
|
简单测试(装好了zsh嘿嘿,eeee催我装,用随机主题的bt!
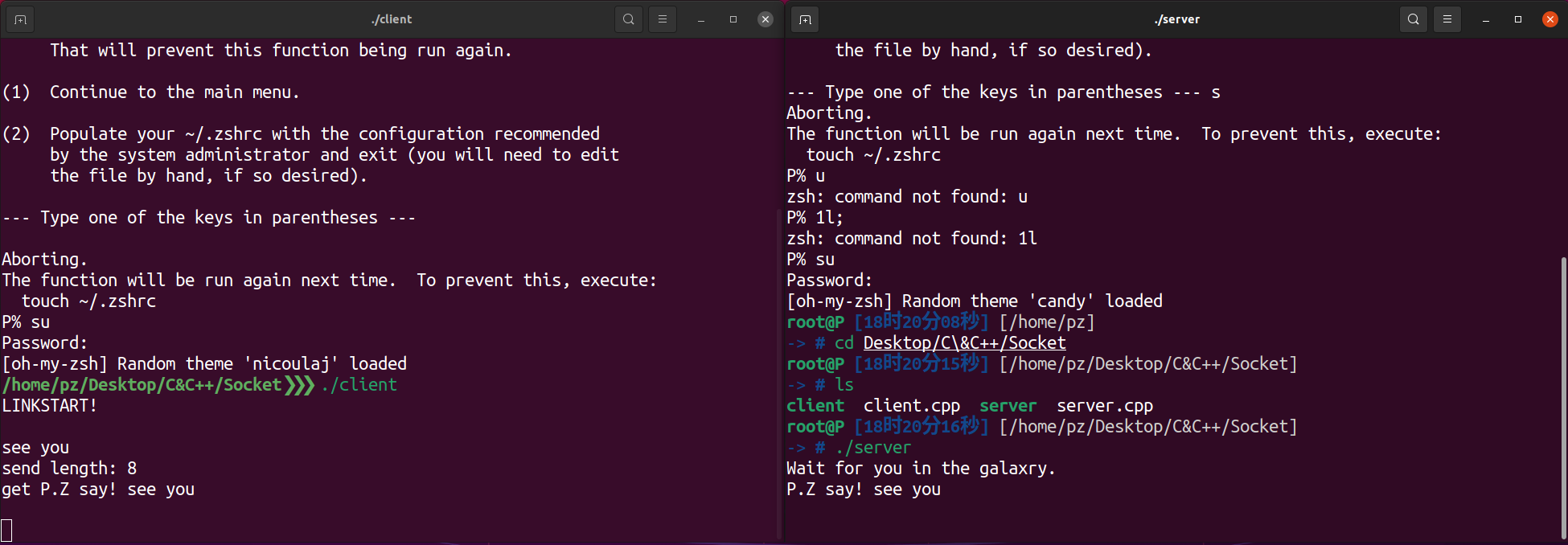
(To be continue…)
login-Socket的审计思考
昨晚拉着eeee以为能解决掉通信细节,但没想到搞gdb从头报错到底,然后就快十二点了
摘录一段其他平台的话,感觉总结的很到位(我不知道是哪个平台
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| 关于fork:
当程序调⽤fork函数时,系统会创建新的进程并为其分配资源;然后,会将原来进程的相关内容全部复制到新的进程中。
fork()函数被调⽤⼀次,但是会返回两次(⽗⼦进程各⼀次)
返回值分析:
1)在⼦进程 中,fork函数返回0
2)在⽗进程中,fork函数返回新创建⼦进程的ID
3)如果出现错误,fork返回⼀个负值
(对1和2的原因分析:①在⼦进程中通过调⽤getppid可以⽅便的知道⽗进程的PID;②没有⼀个函数可以使⽗进程获得其所有⼦进程 的PID。(所以在fork返回时,将⼦进程的PID直接返回给⽗进程))
特点:
1. ⽗、⼦进程共享正⽂段,不共享数据、堆、栈段,⼦进程获得⽗进程数据、堆、栈段的副本。
2. ⼦进程会获得缓冲区的副本,即fork前进程缓冲区中的数据未被flush掉,则fork后,⼦进程能够获得⽗进程缓冲区中的数据。
3. ⽗进程所有被打开的⽂件描述符都会被复制到⼦进程中。 注:fork之后处理⽂件描述符通常有两种情况: ①⽗进程等待⼦进程结束; ②⽗、⼦进程各⾃执⾏不同的正⽂段(⽗、⼦进程各⾃关闭不需要使⽤的⽂件描述符);
4. fork之后⽗、⼦进程的区别: ①fork的返回值; ②进程ID不同; ③⽗进程也不同; ④⼦进程的tms_utime、tms_stime、tms_cutime和tms_ustime均被设置为0; ⑤⽗进程设置的⽂件锁不会被⼦进程继承; ⑥⼦进程的未处理的闹钟被清除; ⑦⼦进程的未处理信号集设置为空集;
5. fork失败的两个主要原因: ①系统中进程数⽬已经达到上限; ②该实际⽤户的进程总数达到系统限制;
13 使⽤⽅法:
①⼀个进程希望复制⾃⼰,使得⽗、⼦进程执⾏不同的代码段。如⽗进程监听端⼝,收到消息后,fork出⼦进程处理消息,⽗进程仍 然负责监听消息。(⽗监听,⼦处理信息)
②⼀个进程需要执⾏另⼀个程序。如fork后执⾏⼀个shell命令。
|
关于login的那题,是创建了一个子进程进行处理数据,父进程负责通信(也就是上述的倒数第二行)
看了s0rry师傅的博客得知,先创建子进程,利用子父进程sys_clone()的返回不同,让子父进程运行不同代码,并且子进程ptrace()附加
Helen师傅的原意是两个进程干不同事情,如果要动调只能gdb调试
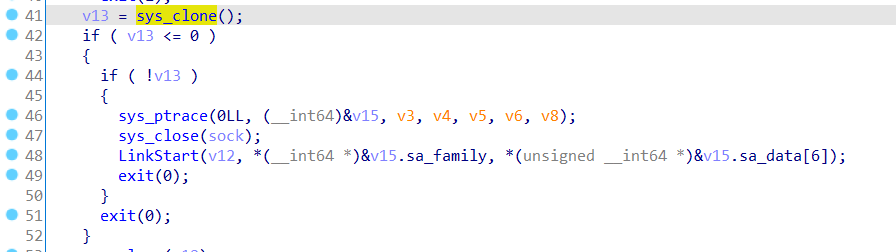
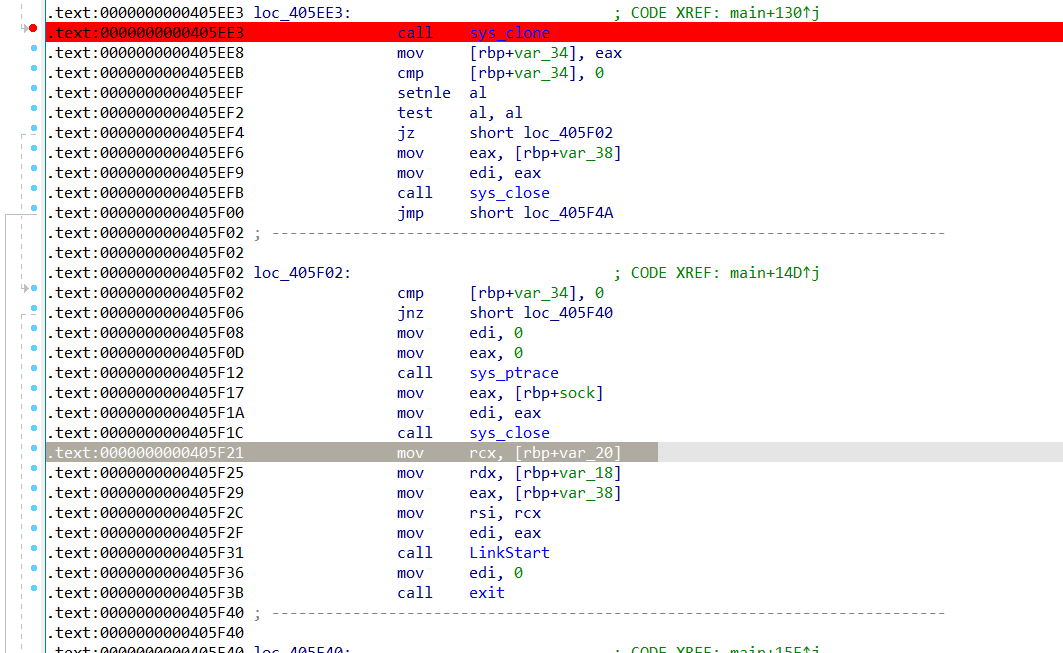
而s0rry师傅给出了一个解法就是直接跳过clone和ptrace
就是在创建子进程这边下断点,然后直接跳到要进入LINKSTART(注意前面几条汇编指令是压入值)
我原本想着一个进程要干两个事情不行,但今天调试了一下发现可以!
可能算是Helen师傅的非预期了
文献参考
https://zhuanlan.zhihu.com/p/405416697
https://www.jianshu.com/p/066d99da7cbd
https://blog.csdn.net/deyuzhi/article/details/51725074
http://s0rry.cn/index.php/archives/18/#menu_index_9